

Introduction
If you have ever typed a question into ChatGPT and received a surprisingly smart, human-like answer, you have probably wondered: how does ChatGPT work, really? What is happening behind the scenes in those few seconds between your question and the response?

Understanding how does ChatGPT work is no longer just a topic for computer scientists. With AI chatbots becoming part of everyday life — helping with writing, coding, answering questions, and much more — this knowledge matters for everyone. In this complete guide, we break down the real science behind ChatGPT in plain, human-readable language, step by step.
Whether you are a student, a business owner, a curious reader, or a developer, by the end of this article you will have a thorough understanding of AI language models, neural networks, training data, and how ChatGPT generates responses so convincingly.
1. What Is ChatGPT?
ChatGPT is an AI-powered chatbot developed by OpenAI. The name stands for Chat Generative Pre-trained Transformer. It was first released to the public in November 2022 and quickly became one of the fastest-growing applications in internet history.
At its core, ChatGPT is a large language model (LLM). It does not browse the internet in real time (unless given a specific plugin or tool), and it does not “think” the way humans do. Instead, it predicts and generates text based on patterns it learned during a massive training process.
Understanding how does ChatGPT work starts with this single key idea: it is a text prediction machine of extraordinary sophistication.
2. The Core Concept: Language Models
A language model is a system trained to understand and generate human language. The simplest version of this idea is autocomplete on your smartphone — when you type “Good morning, how are” and it suggests “you?” — that is a basic language model at work.
ChatGPT is a vastly more powerful version of this idea. Instead of predicting one or two words, it can predict thousands of words in a coherent, contextually aware sequence.
Language models learn from enormous amounts of text. By reading billions of sentences, they learn patterns: which words tend to follow which other words, how sentences are structured, how ideas connect, and how tone changes between formal and informal writing.
The key distinction of modern LLMs like ChatGPT is that they do not simply memorize text. They learn to understand the statistical relationships between words and ideas, allowing them to generate entirely new sentences that have never existed before.
3. How Does ChatGPT Work? Step-by-Step
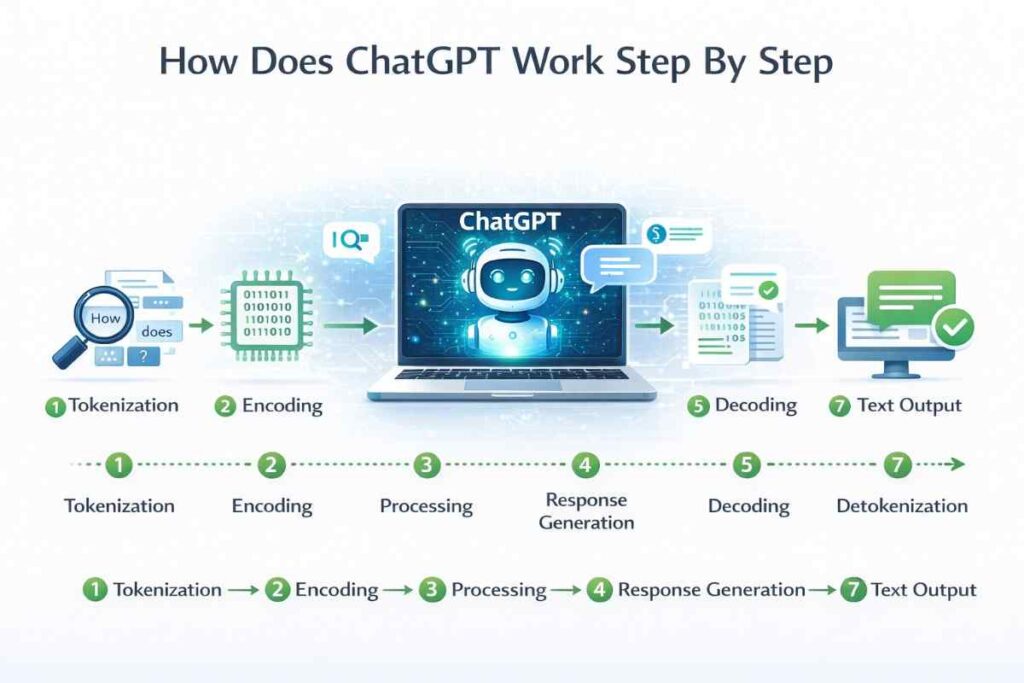
So how does ChatGPT work when you send it a message? The process involves several distinct stages working together in milliseconds.
Step 1 — You type a prompt. Your text is received by OpenAI’s servers as raw input.
Step 2 — Tokenization. Your words are broken down into tokens. A token is roughly 3–4 characters or part of a word. For example, “ChatGPT” might become two tokens: “Chat” and “GPT”. Numbers, punctuation, and spaces also become tokens.
Step 3 — Embedding. Each token is converted into a high-dimensional numerical vector — essentially a long list of numbers. These numbers encode meaning. Similar concepts (like “cat” and “kitten”) end up with numerically similar vectors.
Step 4 — Transformer processing. The sequence of token vectors passes through many layers of a neural network called a Transformer. Each layer refines the model’s understanding of what the text means and what should come next.
Step 5 — Output probability. After all the transformer layers, the model produces a probability distribution over its entire vocabulary — roughly 50,000+ possible tokens. It picks the most likely next token (with some controlled randomness).
Step 6 — Repetition. The model repeats this token-by-token process, appending each new token to the growing response, until it decides the response is complete.
Step 7 — Decoding. The token sequence is converted back into readable human text and sent back to you.
This entire process happens in seconds and typically generates hundreds or thousands of tokens per second on powerful hardware.
4. What Is a Transformer? The Heart of ChatGPT
The Transformer architecture is the single most important concept in understanding how does ChatGPT work. It was introduced in a landmark 2017 research paper titled “Attention Is All You Need” by researchers at Google.
Before Transformers, AI language systems used older architectures like Recurrent Neural Networks (RNNs). These processed text word by word in sequence, which made them slow and limited in their ability to handle long-range dependencies — understanding that a word at the start of a paragraph relates to a word hundreds of words later.
Transformers solved this by introducing a mechanism called self-attention.
What Is Self-Attention?
Self-attention allows the model to look at every word in the input simultaneously and decide which words are most relevant to each other. When processing the word “bank” in the sentence “I deposited money at the bank,” the attention mechanism correctly focuses on “money” and “deposited” — determining this is a financial bank, not a river bank.
This happens through three mathematical components called Query, Key, and Value vectors. Each token generates all three. The Query asks “what am I looking for?” The Key says “here is what I offer.” The Value delivers the actual information. Attention weights are calculated from how well each Query matches each Key, then applied to the Values.
Multi-Head Attention
ChatGPT uses multi-head attention, meaning it runs many attention processes in parallel. Each “head” focuses on a different aspect of the text — one might focus on grammatical structure, another on semantic relationships, another on the topic being discussed. The outputs are combined and passed forward.
GPT-4, the model underlying many versions of ChatGPT, is rumored to use 96 transformer layers and 96 attention heads per layer, though OpenAI has not officially confirmed all architecture details.
5. How ChatGPT Was Trained
Training ChatGPT is a three-phase process:
Phase 1 — Pre-training
OpenAI gathered an enormous corpus of text from the internet, books, academic papers, websites, and more. This dataset contains hundreds of billions of words. The model was trained using a technique called self-supervised learning: it was shown sequences of text and asked to predict the next token. No human labeling was needed at this stage — the text itself served as its own training signal.
During this phase, the model develops a broad, general understanding of language, facts, reasoning, and writing style.
Phase 2 — Supervised Fine-Tuning (SFT)
After pre-training, human trainers wrote example conversations — both the user’s side and the ideal AI response. The model was then fine-tuned on these examples to learn the format of helpful, conversational responses.
This is why ChatGPT sounds like a helpful assistant rather than just a continuation of random internet text.
https://ai.google/discover/large-language-models
Phase 3 — Reinforcement Learning from Human Feedback (RLHF)
This is the most distinctive part of ChatGPT’s training and is explained in detail in the next section.
6. Reinforcement Learning from Human Feedback (RLHF)
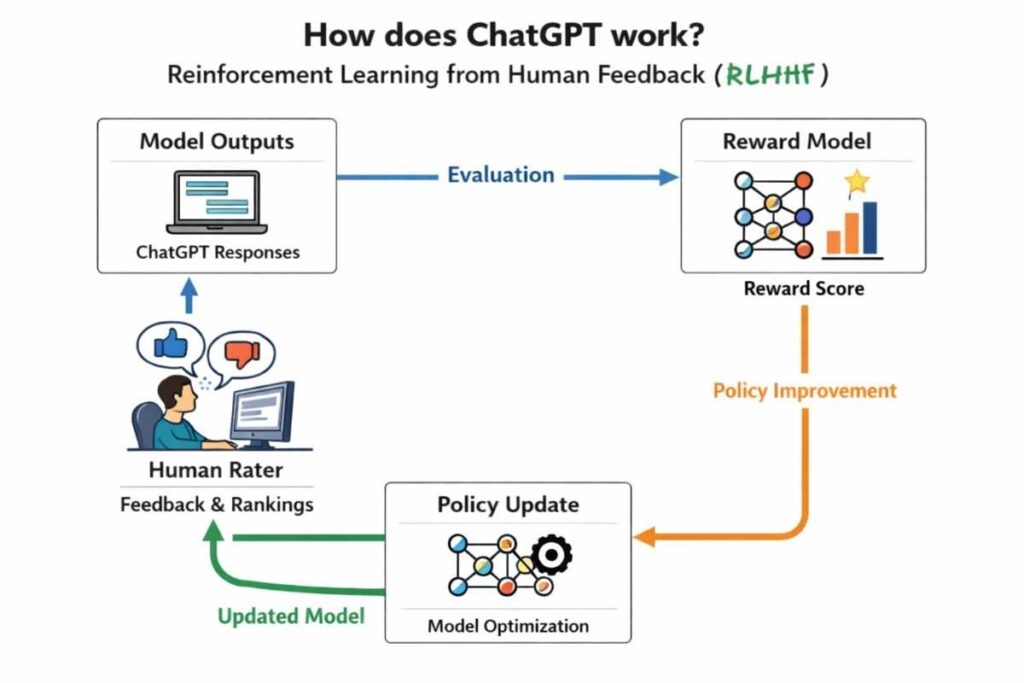
RLHF is the technique that truly makes ChatGPT feel helpful, harmless, and honest — the three goals OpenAI set for the system.
Here is how it works:
Step 1 — Generating multiple responses. For any given prompt, the model generates several different responses.
Step 2 — Human ranking. Human raters read all the responses and rank them from best to worst. “Best” means most helpful, most accurate, most appropriate, and least harmful.
Step 3 — Reward model training. A separate neural network called a reward model is trained to predict human preference scores. Given a response, it outputs a single number representing how much a human would prefer it.
Step 4 — Policy optimization. The main ChatGPT model is then updated using an algorithm called Proximal Policy Optimization (PPO) — a reinforcement learning technique. The model is rewarded for generating responses that the reward model scores highly, and penalized for low-scoring responses.
This loop is repeated many times, nudging the model’s behavior toward responses that humans actually find useful and appropriate.
RLHF is the reason ChatGPT refuses harmful requests, avoids certain topics, and generally behaves more like a responsible assistant than an unconstrained text generator.
7. How ChatGPT Understands Context
One of the most impressive aspects of how does ChatGPT work is its ability to maintain context across a long conversation. This is made possible by the context window.
A context window is the total amount of text the model can “see” at once. For GPT-4, this can be up to 128,000 tokens — roughly the length of a full novel. Every time you send a new message, your entire conversation history (within the context window) is included in the model’s input.
This means ChatGPT does not have memory in the traditional sense. It cannot remember a conversation from last week. But within a single conversation, it reads everything you have both said, which allows it to give contextually appropriate follow-up responses.
This is also why very long conversations can sometimes cause ChatGPT to lose track of earlier details — the context window has physical limits, and older parts of the conversation fall outside its view.
8. Tokenization Explained
To truly understand how does ChatGPT work, you need to understand tokenization in a bit more depth.
ChatGPT does not process letters or words. It processes tokens. OpenAI uses a tokenization method called Byte Pair Encoding (BPE), which works like this:
Wikipedia: Transformer (machine learning model)
Common words become a single token (“the”, “is”, “and”). Less common words are split into subword tokens (“unbelievable” becomes “un”, “believ”, “able”). Very rare words might be split into individual characters.
Why does this matter? Because it means ChatGPT “thinks” in these fractional word units, not full words. When the model generates text, it is picking the next most probable token from its vocabulary of approximately 50,000 tokens — not the next word.
This also explains some quirky ChatGPT behavior. For example, ChatGPT is famously bad at counting letters in words, because it never really “sees” individual letters during normal processing — it sees token chunks.
9. Temperature and Creativity in ChatGPT
When ChatGPT generates a response, it does not always pick the single most probable token. Instead, it uses a parameter called temperature to introduce controlled randomness.
At temperature = 0, the model always picks the highest probability token. Responses are predictable and consistent, but can feel repetitive.
At temperature = 1 or higher, the model sometimes picks lower-probability tokens. This creates more creative, varied, and sometimes surprising responses — but also increases the chance of errors or hallucinations.
OpenAI carefully tunes the temperature used in ChatGPT’s public interface to balance creativity and reliability. More technical API users can set their own temperature values depending on their use case.
A related parameter is top-p (nucleus sampling), which limits the model to only considering tokens whose cumulative probability sums to a certain threshold. Together, temperature and top-p give developers fine-grained control over the style and reliability of ChatGPT’s output.
10. ChatGPT vs Other AI Chatbots: A Comparison
| Feature | ChatGPT (GPT-4) | Google Gemini | Claude (Anthropic) | Llama (Meta) |
|---|---|---|---|---|
| Developer | OpenAI | Google DeepMind | Anthropic | Meta AI |
| Architecture | Transformer (GPT) | Transformer (Gemini) | Transformer (Claude) | Transformer (Llama) |
| Context Window | Up to 128K tokens | Up to 1M tokens | Up to 200K tokens | Up to 128K tokens |
| Training method | Pre-train + RLHF | Pre-train + RLHF | Pre-train + Constitutional AI | Pre-train + RLHF |
| Open Source | No | No | No | Yes (weights released) |
| Multimodal | Yes (text + images) | Yes (text, images, video) | Yes (text + images) | Partially |
| Free tier | Yes | Yes | Yes | Yes (self-hosted) |
11. Limitations of ChatGPT
Understanding how does ChatGPT work also means understanding what it cannot do — and why.
Hallucinations. ChatGPT sometimes generates text that sounds confident but is factually wrong. This happens because the model optimizes for plausible-sounding text, not verified truth. It has no direct access to a fact-checking database.
No real-time knowledge. The base model has a training cutoff date and does not browse the internet unless given a specific tool. It cannot tell you today’s stock price or yesterday’s news from its core model.
Lack of true reasoning. ChatGPT can often solve math problems and logic puzzles, but this is pattern matching at a sophisticated level — not the kind of step-by-step formal reasoning humans use. It can make errors on problems that require strict symbolic logic.
Sensitivity to phrasing. Small changes in how a question is phrased can lead to very different answers. This is because the model is highly sensitive to the exact token sequence in its input.
Bias. Because ChatGPT was trained on human-generated text, it can reflect biases present in that text. OpenAI has worked hard to reduce harmful biases through RLHF, but cannot eliminate them entirely.
12. Real-World Applications
Knowing how does ChatGPT work gives you a better sense of where it excels in real-world use:
Writing assistance. ChatGPT can draft emails, articles, essays, marketing copy, and more. Its strength is generating fluent, coherent text quickly.
Coding help. Because it was trained on vast amounts of code, ChatGPT is remarkably effective at writing, debugging, and explaining code across dozens of programming languages.
Education. Students use ChatGPT as a tutor — asking for explanations of difficult concepts, worked examples of math problems, or summaries of complex topics.
Customer support. Businesses deploy ChatGPT-powered chatbots to handle common customer inquiries, freeing human agents for complex issues.
Research assistance. ChatGPT can summarize papers, suggest research directions, and help brainstorm — though its tendency to hallucinate means its outputs must always be verified.
Creative writing. From poetry to fiction to game dialogue, ChatGPT is a powerful creative collaborator when guided well.
FAQs
Q1: How does ChatGPT work in simple terms? ChatGPT works by reading your text, breaking it into small chunks called tokens, passing those tokens through dozens of layers of a neural network that weighs the relationship between all the words, and then predicting — one token at a time — the most appropriate next word until a full response is formed.
Q2: Does ChatGPT actually understand language? It depends on your definition of “understand.” ChatGPT does not have consciousness or awareness. However, it has learned extraordinarily deep statistical patterns in human language that allow it to respond in ways that look and feel like genuine understanding. Most AI researchers describe it as a very powerful pattern-matching and text prediction system.
Q3: How does ChatGPT know so much? ChatGPT was trained on hundreds of billions of words of text from the internet, books, academic papers, and more. Through this training, it absorbed a vast range of human knowledge — from history and science to cooking recipes and programming syntax.
Q4: Can ChatGPT learn from my conversations? No, not in real time. ChatGPT does not update its weights based on individual conversations. It can remember what you said earlier in the same conversation (within its context window), but once the conversation ends, that information is gone. OpenAI may use conversation data for future model training, subject to its privacy policy.
Q5: Why does ChatGPT sometimes give wrong answers? This is called a hallucination. Because the model is trained to generate plausible, fluent text — not verified facts — it can sometimes produce confident-sounding statements that are inaccurate. This is a known limitation of all large language models and is an active area of AI safety research.
Q6: How does ChatGPT differ from a search engine? A search engine retrieves existing web pages that match your query. ChatGPT generates brand new text responses. A search engine shows you what exists; ChatGPT synthesizes and composes something new. This makes ChatGPT very powerful for writing and reasoning tasks, but less reliable than a search engine for finding specific, verified facts.
Conclusion
Understanding how does ChatGPT work reveals something remarkable: a technology that feels almost magical is actually built on elegant, well-understood mathematical principles — transformers, attention mechanisms, probability distributions, and feedback from millions of human interactions.
ChatGPT does not think. It does not feel. But it has learned from an incomprehensible volume of human thought, and that training has given it the ability to be a genuinely useful partner for writing, learning, coding, and problem-solving.
As AI continues to evolve rapidly through 2026 and beyond, understanding these foundations will help you use these tools more effectively, evaluate their outputs more critically, and participate more meaningfully in conversations about AI’s role in society.
Ready to go deeper? Try asking ChatGPT directly about how it works — and notice how the explanation it gives matches (or differs from) what you just learned here. That meta-experiment alone is a fascinating window into the technology.

